本周写一篇科研笔记,阐述滴滴派单算法背后的核心思想,展示一种以运筹优化(Operations Research & Mathematical Programming)为核心的 AI 视角,从而拓宽对AI的理解,避免局限在传统Machine Learning/Deep Learning的“桎梏”中。
 (a) Ride-hailing vehicle clustering |  (b) Dispatching difficulty |
网约车平台的核心问题之一是,如何把订单分配给合适的司机?这一过程被称为Order Dispatching(派单)。派单效果会直接影响用户等待时间,司机收入,平台成交率,用户体验等。
解决派单问题,一种非常直接的思路是:最近司机接最近订单。但这种贪心策略过于短视(myopic),有时会造成供给侧接不到单(如图a)或需求侧打不到车(如图b)。其本质原因在于,当前的决策会影响未来的供需结构。因此,在进行派单时,不仅要考虑当前收益,还需要考虑未来影响。
1 打车流程回顾
用户侧:
- 用户输入起点和终点
- 平台进行价格预估
- 用户提交订单
- 系统指派合适的司机
- 司机接驾
- 完成订单
平台侧:
- 为订单用户搜索附近可用司机
- 预测接驾时间
- 评估不同匹配方案
- 完成订单分配
现实中的派单并不是“订单一来立刻派单”,而通常采用Batch Dispatch(批量派单),即:每隔几秒钟收集一批订单和司机,统一进行优化匹配。
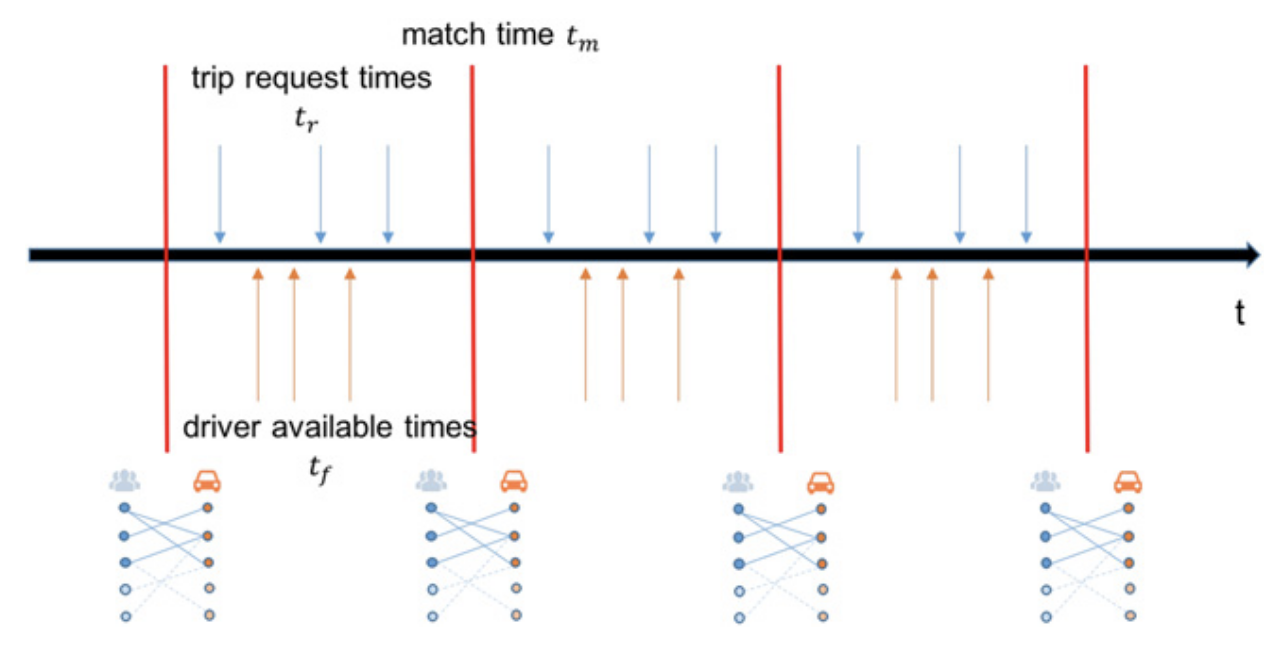
2 派单问题的数学模型
对于每一个batch,记用户数量为J,可用司机数量为I,派单问题可以用如下二部图(Bipartite graph)表示
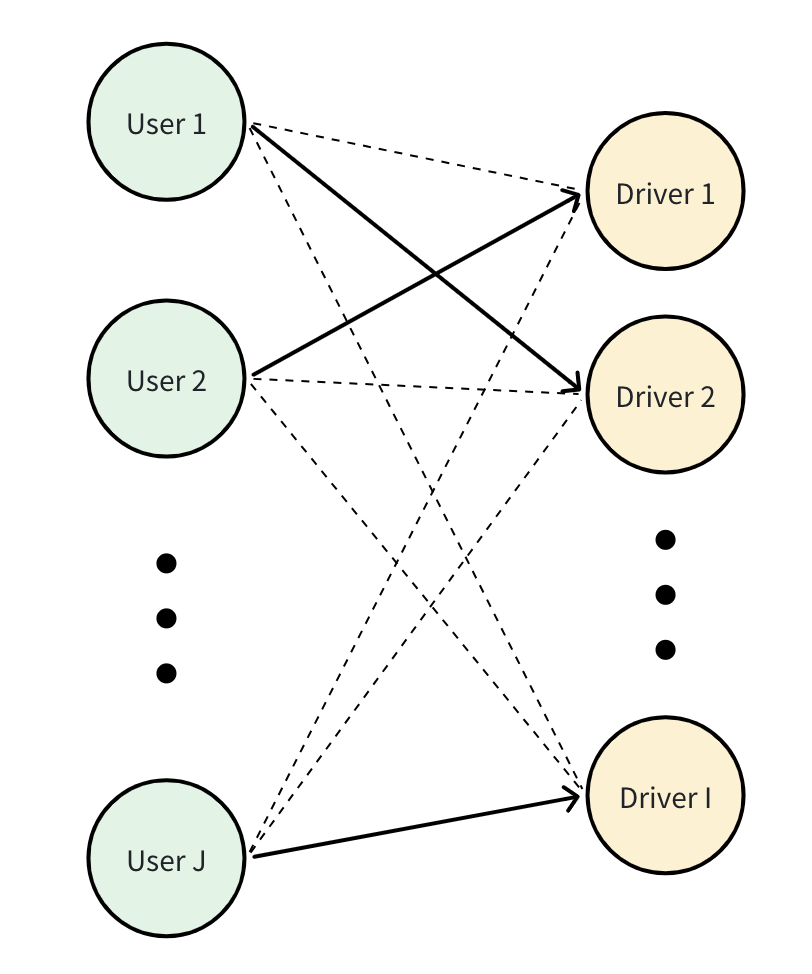
其中,左侧节点是用户,右侧节点是司机,边表示对应派单决策。同时,每条边带有一个“价值”。
记$x_{i,j}=1$表示用户j指派给司机i。因此,为最大化总体收益,上述派单问题可以建模为

其中,约束(2)表示每位司机至多接一个用户。约束(3)表示每位用户至多被指派给一个司机。
Remark 1:
这个问题很有意思,表面上看其决策变量是binary的(离散),并不容易求解。而实际上,这个问题约束的系数矩阵具有全单模性(Total Unimodularity),直接求解其线性规划松弛就等价于求解原来的离散优化问题。
Remark 2:
在早期的系统中,$w_{i,j}=-\text{pickup distance}$,即基于最小化接送距离进行派单。后来慢慢加入了订单价格、等待时间,变成$w_{i,j}=\lambda_1 \cdot \text{fare} -\lambda_2 \cdot \text{pickup distance} - \lambda_3 \cdot \text{waiting time}$。但随着系统运行,越来越发现无论怎么调整这些系数,总是会出现某些区域订单很多而司机不足,或者某些区域订单很少而司机非常多。其本质原因在于模型过于短视,只考虑当前最优,而忽略了当前派单决策会直接影响未来的司机分布。
3 多智能体强化学习
Motivation:平台的目标是最大化长期收益。在实时运行中,由于当前派单决策会影响未来司机分布,如果能直接用一个模型来预测每条边对应的长期价值,那么似乎问题就解决了。
3.1 前处理
基于六边形网格,对城市空间位置进行离散化
将调度时间轴离散化
3.2 模型
将每位司机视为一个agent,首先定义如下
- 状态(State):$s_t=(location, time)$
- 动作(Action):$a_t$,接哪个订单或不接单
- 奖励(Reward):$r=fare$
然后,有以下概念
- 状态转移:$s_t \rightarrow s_{t+1}$
- 价值函数:$V(s_t)$,表示从当前状态开始,未来长期收益
价值函数我们无法写出closed form,强化学习的核心任务就是通过训练来近似得到这样一个“函数”
3.3 训练方法
(1)离线训练
(2)数据集:历史订单轨迹,$(s_t, a_t, r_t, s_{t+1})$
| 时刻 | 位置 | 接的订单 | 当前收益 | 下一位置 |
|---|---|---|---|---|
| 18:00 | 陆家嘴 | 去虹桥 | 80 | 虹桥 |
| 18:40 | 虹桥 | 去静安 | 60 | 静安 |
| 19:10 | 静安 | 去徐汇 | 50 | 徐汇 |
(3)Baseline算法: 时间差分学习(Temporal Difference Learninng)
- 当前价值 = 当前收益 + 下一状态的价值,即$V(s_t) = r + \gamma V(s_{t+1})$,其中$\gamma$是折扣因子,用于反应远期和近期的不同重要程度
- 训练流程:
- Step 1: 初始化$V(s) = 0$
- Step 2: 计算时间差分目标,$y = r + \gamma \textcolor{red}{V(s_{t+1})}$
- Step 3: 计算时间差分误差,$\delta = y - V(s_t)$
- Step 4: 更新Value Function,$V(s_t) \leftarrow V(s_t) + \alpha \delta$,其中$\alpha$是学习率
- Step 5: Goto Step 2,并重复这一过程直至收敛
- 最终产物:一个tabular,存储了不同状态下的价值(所有司机共享)
Remark 3:
使用tabular有三个弊端
状态空间太大
数据稀疏,有些区域几乎没有司机经过
不能泛化,只能应对已经发生过的状态
(4)Cerebellar Value Network
- 不再用tabular存储每个状态下的价值,而是用神经网络直接映射,即$V_{\theta}(s)$
- 训练流程:
- Step 1: 初始化$V_{\theta}(s)$
- Step 2: 计算时间差分目标,$y = r + \gamma \textcolor{red}{V_{\theta}(s_{t+1})}$
- Step 3: 计算Loss,$(y - V_{\theta}(s_t))^2$
- Step 4: 反向传播更新神经网络参数
- Step 5: Goto Step 2,并重复这一过程直至收敛
- 最终产物:一个输入为司机状态,输出为未来长期价值的神经网络
Remark 4:
采用NN的方式相比tabular,具有以下优势
- 增加了泛化能力,可以输出历史数据中没有的状态的价值
- 除了状态之外,还可加入其他特征,如天气等
3.4 预测
- 对于每一条边,可得出司机完成订单后的状态$s_{t+1}$
- 利用训练好的价值函数进行预测,$V(s_{t+1})$
- 计算二部图中边的价值,$w_{i,j}=fare_{i,j} + \gamma V(s_{t+1})$
4 总结
4.1 派单算法运行流程
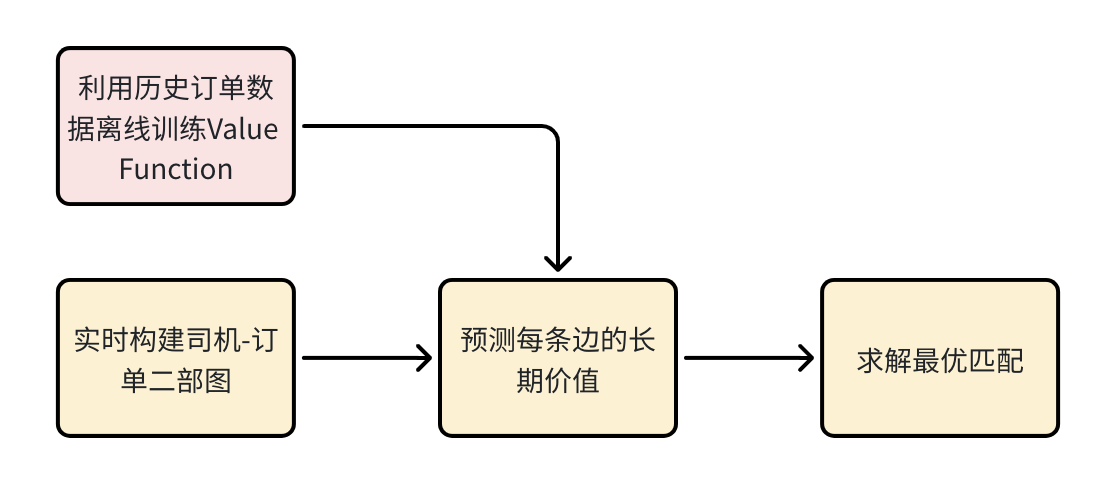
4.2 算法设计的思路
- 传统优化算法,利用数学性质来实现高效求解
- 为解决过于短视的问题,引入RL来预测司机状态价值,并使用时间差分学习进行训练
- 为解决状态空间巨大的问题,引入NN来逼近Value Function
Reference
[1] Qin, Z., Tang, X., Jiao, Y., Zhang, F., Xu, Z., Zhu, H., & Ye, J. (2020). Ride-hailing order dispatching at didi via reinforcement learning. INFORMS Journal on Applied Analytics, 50(5), 272-286.